


Building a working Instagram clone using Flutter and Firebase
This is an overview of how I used Flutter and Firebase to create a photo sharing application using Flutter and Firebase.
medium.com

This is an overview of how Flutter and Firebase was used to create a photo sharing application.
Oh no, another Instagram clone?
Most of the clones I’ve come across are either just UI challenges or lacking in features. This project, however, is a more complete Instagram experience with feed, comments, Stories, Direct Messaging, push notifications, post deletion, user reports, account privacy, and more. It is also available for download on iOS and Android.

You can download the application here.
I will be focusing on just the core topics, and will be skipping topics such as Firebase Auth, Cloud Storage and Firebase Cloud Messaging, since there are already several articles and tutorials about them.
I am also not going to discuss most of the UI elements, except for those I find most challenging.
In each section, I will try to highlight the main takeaways.
Project architecture
This section is just to give a brief high level view of the project.
The project architecture is simple and consists of two main folders: ui and services.
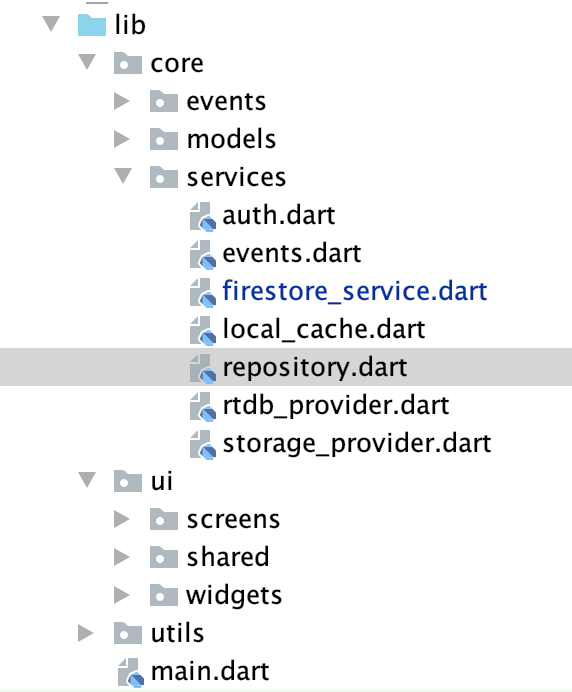
The ui folder is broken down to three parts: screens, widgets, and shared.
Screens are top-level widgets that displays all the UI in one screen on the device.
Sometimes screens contain widgets with a lot of code, so those widgets are abstracted into their respective files in the widgets folder.
Some widgets are reused in multiple screens, such as a loading indicator or a custom scroll view, and these widgets are placed in the shared folder.
The services folder contains files that handle Firebase services such as Firestore, Cloud Storage and Firebase Auth.
It also contains the repository, which is an abstraction layer for the app UI to access. For every function in any of the services file that is needed in the app UI, there is a function in the repository that references that function.
In every file pertaining to the app UI (screens and widgets) that needs to use cloud services, only the repository is imported.
Widgets do not know about the other files in the services folder.
Data Modeling
The models folder that contains the data objects: user, post, comment, etc.
The data objects that are meant to be fetched from Firestore typically have a helper factory constructor that takes a DocumentSnapshot as a parameter:
factory Post.fromDoc(DocumentSnapshot doc) {
return Post(
id: doc.documentID,
...,
timestamp: doc['timestamp'],
metadata: doc['data'] ?? {},
caption: doc['caption'] ?? '',
);
}This way, we can fetch post objects from firestore documents like so:
///Mock function
final QuerySnapshot snap = await shared.collection('posts').get();final List<Post> posts = snap.docs.map((doc) => Post.from(doc)).toList();Database Design
The database used for this project is Firestore. Why? Because…
- Firestore is the newer cousin of realtime database, and has better scalability and data modeling. More info here.
- Firebase is an early supporter of Flutter, making their plugin available on pub.dev from the start.
- Reads > Writes.
The main approach is structure the database in a way that is easy to fetch the required data. The biggest problem to overcome was the limited query capability of Firestore.
Unlike other database solutions you cannot easily query something like “fetch recent posts of users I follow” for the feed screen.
The A-ha! moment was when I realise that a screen should only fetch data from a single data “bucket”. In this case, the query simply boils down to “fetch documents from my feed collection” .
In a social media app like Instagram, reads > writes. A user may read hundreds of documents before committing a single write (post, like, comment, follow/unfollow).
That is why it is a good idea to do all the hard work within the write operations, and keep read operations simple.
When a user uploads a post, the post is written in every single follower’s feed. In other words, data is being duplicated.
Yes, this means a user with millions of followers will cost a lot more than the typical user. Writing to a million followers’ feeds costs roughly $1.80, but the value that someone who has gathered that many followers brings to the social platform is probably much greater than that.

This way, you can easily fetch documents from a single collection ordered by their upload date, and paginate as needed.
The downside to this database structure is that due to data duplication, extra steps are needed if, let’s say, a user makes changes to a document.
What if the user changes the caption of a post, or worse, make changes to their profile picture or username? How would these changes be reflected on previous posts on their followers’ feed? How would you write a post to a follower’s feed?
Enter cloud functions.
Cloud Functions
The main idea is to use a trusted server to deploy code and avoid writing client-side code when you can .
How would you write to everyone’s feed when a new post is uploaded?
A user might have thousands of followers and thousands of posts. If the user makes changes to their profile or any of their posts, we must also propagate such changes to every follower’s feed.
This kind of operation is called a fan-out operation, where a document is duplicated across multiple nodes(references) in the database.
How to fan-out a new post to followers’ feed:
- Get the post uploader’s followers.
- For each follower, create a document reference using the post id for the document id.
- Write the post data to that reference
- Optional — write the new post to your own feed
In any fan-out operation, it is a good idea to use batched writes. However, each batch can have a maximum of 500 operations, so you will need multiple batches for a fan-out operation requiring more than that.
Another use of cloud function is to update a post’s like counter.
A post’s like count may be subject to abuse if it were controlled by client-side code. Instead, we use a cloud function that listens to a document being created or deleted in the “likes” subcollection, and changes the post’s like counter accordingly using FieldValue.increment :
A crucial use of cloud function is for sending push notifications via firebase cloud messaging(FCM). This sendFCM function is called in each relevant exported function (post like, comment like, follow event, comment reply, direct message):
The backend is the backbone of an app. You will need to plan and structure your database properly alongside the querying needs of the app. Before you make your app pretty, make it work.
Let’s move on to the UI side of things. The UI section will also contain some database design stuff that I have not covered earlier.
Root PageView and homepage
The root widget is a PageView, the first page being the editor, the second the main homepage with all the navigation tabs and the third being the direct messaging screen.

You can switch between pages by swiping or pressing the top most navigation buttons. Set the initial page of the page view to 1, the homepage.
If you want to mimic the navigation behavior seen on the Instagram’s iOS app, you should use a CupertinoTabScaffold and a CupertinoTabView for every tab in the homepage. Each tab view handles its own navigation stack, which is important if you want to browse multiple tabs at a time.
However, I encountered a weird bug with focusing on the text field on the editor screen when using CupertinoTabView, so I used a custom navigation solution by Andrea Bizzotto, which got rid of the bug.
To pop the navigation stack to the bottom-most route in the homepage, you need to create a global navigator key for each tab view:
Map<TabItem, GlobalKey<NavigatorState>> _navigatorKeys = {
TabItem.feed: GlobalKey<NavigatorState>(),
TabItem.search: GlobalKey<NavigatorState>(),
TabItem.create: GlobalKey<NavigatorState>(),
TabItem.activity: GlobalKey<NavigatorState>(),
TabItem.profile: GlobalKey<NavigatorState>(),
};Assign tab view with a navigator key. You will need to do this even if you are using CupertinoTabView.
///Home(Feed) TabNavigator(
key: _navigatorKeys[TabItem.feed],
...)///Search TabNavigator(
key: _navigatorKeys[TabItem.search],
...)You then use the BottomNavigationBar’s onTap(index) callback to choose which stack you want to pop:
///Make sure the tab you are pressing is the current tab
if(tab == currentTab)///Pop until first
_navigatorKeys[tab]
.currentState
.popUntil((route) => route.isFirst);Want a screen to scroll to top? You will need to create a scroll controller for each tab:
final feedScrollController = ScrollController();
....
final profileScrollController = ScrollController();Assign the main scroll view widget to a scroll controller (ignore the initialRoute and onGenerateRoute if using CupertinoTabView):
///My Profile Screen
Navigator(
key: _navigatorKeys[TabItem.profile],
initialRoute: '/',
onGenerateRoute: (routeSettings) {
return MaterialPageRoute(
builder: (context) => MyProfileScreen(
scrollController: profileScrollController,
),
);
},
),In BottomNavigationBar’s onTap(index) callback, you can choose which controller you want to scroll to top:
if(tab == currentTab) {switch (tab) {
case TabItem.home:
controller = feedScrollController;
break;
...
case TabItem.profile:
controller = profileScrollController;
break;
}
///Scroll to top
if (controller.hasClients)
controller.animateTo(0, duration: scrollDuration, curve: scrollCurve);
}Feed
The main widget is the post list item widget:

- Header
- Photo PageView
- Engagement Bar (Like, Comment and Share buttons)
- Caption (not shown)
- Like count bar
- Comment count bar
- Top comments
- Timestamp
If you are wondering: The button that looks like a whirlpool allows you to doodle on a post. You can see what other people have drawn.
The data for header, photo page view, caption and timestamp can be fetched directly from the post document located in the feed collection: users/{userId}/feed/{postId}.
The engagement bar is tricky because of the like button. The like button changes in color depending on if you have liked the post or not.
First, create a function that return a stream of a DocumentSnapshot using firestore snapshots() property:
///Check if current user has liked a post
///Returns a stream, such that didLike = snapshot.data.exists
///auth.uid refers to the current logged in user's user idStream<DocumentSnapshot> myPostLikeStream(Post post) {
final ref = postRef(post.id).collection('likes').document(auth.uid);
return ref.snapshots();
}Use this stream within a StreamBuilder to display a reactive UI that correctly reflects if the like button has been pressed or not:
StreamBuilder<DocumentSnapshot>(
stream: Repo.myPostLikeStream(post),
builder: (context, snapshot) {
if (!snapshot.hasData) return SizedBox(); ///If the document exists, post has been liked by current ///logged in user final didLike = snapshot.data.exists;
return LikeButton(
onTap: () {
return didLike
? Repo.unlikePost(post)
: Repo.likePost(post);
}, ///Button appearance icon: didLike ? FontAwesome.heart : FontAwesome.heart_o,
color: didLike ? Colors.red : Colors.black,
);
}),The beauty of this is that even if you are looking at the same post across multiple screens or devices, the state of the all the like buttons on multiple screen is correctly being reflected.
Also, as an added bonus, due to firestore’s offline capabilities, the like button will still react to user presses even if you are offline!
You can apply the same principle to similar widgets like the follow/unfollow button found in the profile page.
Sometimes there are parts of the UI that appear different depending on the user viewing it. In these cases, try to use a StreamBuilder for a reactive experience.
If the UI is mainly static and is the same for anyone looking at it (like post caption or photos), you can just fetch data the normal way.
The post stats (like count, comment count) are stored elsewhere, and it must be fetched separately. This posts collection exists as a separate root level collection and is not a subcollection of the users collection.
Future<PostStats> getPostStats(String postId) async {
final ref = shared.collection('posts').document(postId);
final doc = await ref.get();
return !doc.exists ?
PostStats.empty(postId) : PostStats.fromDoc(doc);
}Why not store the stats in same place where the post document is located?
Because the stats are very prone to changes and hence should not be duplicated.
Could you imagine updating every follower’s feed every time a post is liked or someone makes a comment?
For the top comments, you will need to query for the comments within the post’s comments subcollection:
Future<List<Comment>> getPostTopComments(String postId, {int limit}) async {
final ref = shared
.collection('posts')
.document(postId)
.collection('comments')
.orderBy('like_count', descending: true)
.limit(limit ?? 2);
final snap = await ref.getDocuments();
return snap.documents.map((doc) => Comment.fromDoc(doc)).toList();
}Yes, you can try to store the top comments as an array on the same post document, but it will require writing a complex cloud function that listens to comments being created or deleted, as well as listening to changes in their like count, and finally updating/sorting the post’s top comments array as needed. On top of that, you will also need to update every follower’s feed too.
This means that multiple reads are required to fetch a single post. This is absolutely fine, considering the alternative of putting all the data in one document, and having to update potentially thousands of documents for every single like, comment or change. Remember, not all your followers will be reading/fetching your new post, but any fan-out operation will have to be propagated to every single one of your followers.
In the pursuit of optimizing read operations, you might instead find yourself making things a lot harder and costlier that it should be.
You should think of the post widget as not a single widget, but multiple widgets combined, each with data coming from different sources or “buckets”. This helps in data modeling too, since it uses several data objects, instead of a single overly bloated post object.
State Management
I have tried using BloC and Provider packages to maintain application state. However, I found that using a StreamBuilder for this project is simpler, especially considering firestore already provides streams of DocumentSnapshot (single document) and QuerySnapshot (multiple documents).
In some cases, I found using an EventBus is useful, especially when you need to show toast messages or update the UI upon a successful post upload or delete.
In most widgets where you only need to load data once and not listen to document changes, you can just simply use setState().
Take for example the widget that displays another user’s posts in their profile page. In its initState(), call a function that fetches posts:
@override
initState() {
_getPosts(); super.initState();
}The UI automatically updates and displays posts upon calling setState():
_getPosts() async {
setState(() {
isLoadingPosts = true;
}); final PostCursor result = await Repo.getPostsForUser(
uid: uid,
limit: 8,
); if (mounted)
setState(() {
isLoadingPosts = false;
posts = result.posts;
startAfter = result.startAfter;
});
}The PostCursor object is a helper class used for pagination, which I will get back to later. It simply contains a list of posts List<Post> and a DocumentSnapshot of the last document fetched.
The isLoadingPosts variable is just a flag to tell the UI when to show a loading indicator.
This pattern of fetching data in initState() and then updating the UI with fetched data can be found in many other screens.
It is always a good practice to check if(mounted) property before calling setState(), and if you do not want to call if(mounted) multiple times, simply override your StatefulWidget’s setState():
@override
void setState(fn) {
if(mounted)
super.setState(fn);
}Sometimes, calling setState() is not enough. A related example would be in the current logged in user’s profile screen, where we not only need to fetch posts, but also update the UI accordingly when a post is uploaded.
We can use aStreamBuilder for this, however, it is hard to paginate with a StreamBuilder. Don’t want to paginate your data? What happens if the current logged in user has thousands of posts? Every time the profile screen is loaded, all of the posts are loaded at once via the stream. This is both costly from a billing and bandwidth perspective.
The solution? Use a combination of a stream and setState();
Like in the previous example, we first fetch some posts upon loading. Additionally, use a stream to listen to any new posts in the database and add the post to the UI.
Create the stream and attach a listener to it in initState(); if a new post is uploaded, update the UI:
final postStream = Repo.myPostStream();List<Post> posts = [];@override
void initState() {
_getPosts();
postStream.listen((data) {
data.documents.forEach((doc) {
if (initialPostsLoaded) {
final post = Post.fromDoc(doc);
if (post == null) return;
setState(() {
posts = [post] + posts;
});
}
});
});
eventBus.on<PostDeleteEvent>().listen((event) {
setState(() {
posts = List<Post>.from(posts)
..removeWhere((p) => p.id == event.postId);
});
});
super.initState();
}The stream listens only to the newest document in the posts collection:
Stream<QuerySnapshot> myPostStream() {
final ref = userRef(auth.uid)
.collection('posts')
.orderBy('timestamp', descending: true)
.limit(1);
return ref.snapshots();
}For post deletes, I choose to use an Event Bus listener. When a post deletion is complete, the UI searches for a post with the id and removes it from view.
There are many ways to manage state. There are some popular state management solutions that I have not tried, like RxDart. Choose the one that accomplishes what you want without being overly complicated. Don’t use BloC for a simple counter app — most of the times, setState() will do the trick. But also think about if the solution you choose will still be manageable in the future.
Pagination
I created a simple helper class to help with posts related pagination.
class PostCursor {
final List<Post> posts;
final DocumentSnapshot startAfter;
final DocumentSnapshot endAt;
PostCursor(this.posts, this.startAfter, this.endAt);
}We can use this class in our services files like so:
Future<PostCursor> getFeed({DocumentSnapshot startAfter}) async {
final uid = Auth.prof.uid;
final query = startAfter == null
? userRef(uid)
.collection('feed')
.orderBy('created_at', descending: true)
.limit(8)
: userRef(uid)
.collection('feed')
.orderBy('created_at', descending: true)
.limit(14)
.startAfterDocument(startAfter);
final docs = await query.getDocuments();
final posts = docs.documents.map((doc) => Post.fromDoc(doc)).toList();
return docs.documents.isNotEmpty
? PostCursor(posts, docs.documents.last, docs.documents.first)
: PostCursor(posts, startAfter, null);
}This way, screens only need deal with a single data object that contains all the necessary data to display widgets and to paginate. Minimize business logic in your widgets.
For screens that has a pull to refresh as well as a load more features, I created a custom scroll view which reacts to an overscroll. You can use other libraries to achieve the same results.
The main thing is to use a CustomListView and declare its slivers.
I used a CupertinoSliverRefreshControl for an iOS look and feel for the pull to refresh feature.
Place your ListView or any widget that extends ScrollView inside the SliverToBoxAdapter.
Lastly, place a loading indicator inside another SliverToBoxAdapter and only show it only when the screen is loading more data.
Since the default ClampingScrollPhysics() behavior on Android is not the one we want, we need to specify BouncingScrollPhysics() so the onRefresh and onLoadMore callbacks can get called from the overscroll.
The downside to using this is that every time you place a ListView inside the CustomScrollView, you will need to set shrinkWrap: true , which has reduced performance. Also, set the ListView’s physics to NeverScrollablePhysics() if you don’t want it to scroll independently from its parent.
Direct Messaging Screen
A chat screen by itself would be enough if the only way to access it is by pressing the message button on a user profile. However, just like in Instagram, we want a Direct Messaging(DM) screen that shows all active chats.
The DM data bucket does not contain the actual messages, but maintains documents containing users that you have chatted with in the past.

Additionally, each document maintains several fields that provides some crucial information.
The last_checked field contains the last message sent in the conversation.
The last_seen_timestamp refers to the last time the user has opened the conversation.
Since the DM screen needs to react to new messages, we use a stream and a StreamBuilder to feed data into a ListView. We also sort the data using the recency of the last_checked_timestamp, so that the latest conversations appear at the top.
StreamBuilder<QuerySnapshot>(
stream: Repo.DMStream(),
builder: (context, snapshot) {
if (!snapshot.hasData) {
return LoadingIndicator();
} else {
final docs = snapshot.data.documents
..sort((a, b) {
final Timestamp aTime =
a.data['last_checked_timestamp'];
final Timestamp bTime =
b.data['last_checked_timestamp'];
return bTime.millisecondsSinceEpoch
.compareTo(aTime.millisecondsSinceEpoch);
}); return docs.isEmpty
? EmptyIndicator('No conversations to show')
: ListView.builder(
shrinkWrap: true,
physics: NeverScrollableScrollPhysics(),
itemBuilder: (context, index) {
final doc = docs[index];
...To mark a conversation with unread messages in our ListView, we check to see if the last_checked_timestamp is greater than our last_seen_timestamp.
final Timestamp lastCheckedTimestamp =
doc['last_checked_timestamp'];final Timestamp lastSeenTimestamp =
doc['last_seen_timestamp'];///auth.uid refers to current logged in user's idfinal hasUnread = (lastSeenTimestamp == null)
//If no last_seen_timestamp exists, it must be a new conversation
? lastCheckedSenderId != auth.uid
//if i didn't send the message, check if I have seen the most recent //checked message
: (lastSeenTimestamp.seconds <
lastCheckedTimestamp.seconds &&
lastCheckedSender != auth.uid);The last_seen_timestamp gets updated every time the chat screen is opened and there is a new message from the other user.
Now we have all necessary information to display our conversations, sorted by recency, and unread messages:
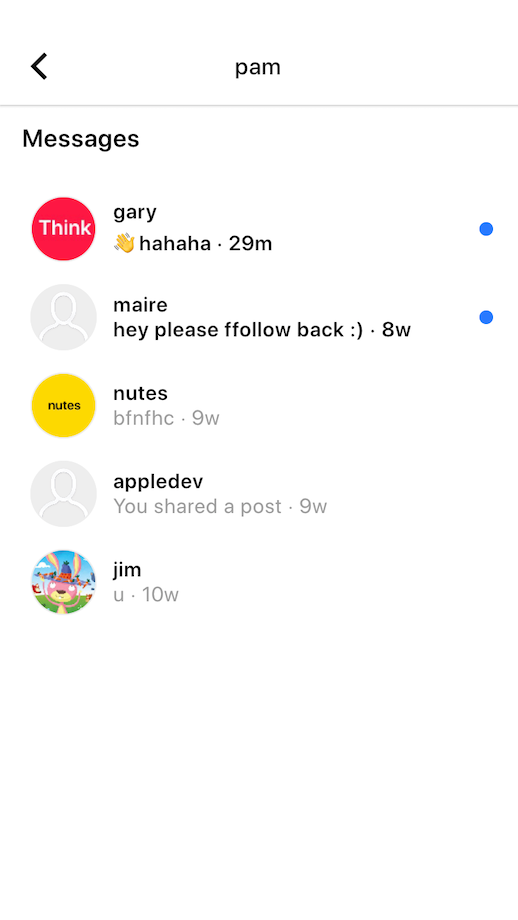
Lastly, I used the flutter_slidable package to allow users to delete conversations by sliding the list view item.
The is_persisted field indicates whether the conversation has been deleted from a user’s DM screen. The stream that powers the DM screen fetches documents that have that field set to true.
Stream<QuerySnapshot> DMStream() {
return userRef(auth.uid)
.collection('chats')
.where('is_persisted', isEqualTo: true)
.snapshots();
}When a user deletes a conversation, the is_persisted field is set to false, and a new field end_at is added, with its value set to Timestamp.now().
Future deleteChatWithUser(String userId) async {
final selfId = auth.uid;final selfRef = userRef(selfId).collection('chats').document(userId);final payload = {
'is_persisted': false,
'end_at': Timestamp.now(),
};return selfRef.setData(payload, merge: true);
}This new field allows us to only load messages up to certain date when the user decides to reopen the conversation after it was deleted on their end.
Take note that the actual messages do not get deleted, instead, only the chat session is removed from that user’s DM screen, and the user will never see messages earlier than the date of deletion. This mimics the behavior found in Instagram.
Chat Screen
When a user taps an item on the DM screen, they are directed to the chat screen, where the actual messages are shown.
The first step before loading the messages is to get the chat id. The chat id is a combination of two user ids. This is so that we can easily make a reference to a conversation without having to make an additional query. In initState(), we take both user ids, sort them, and join using a hypen:
chatId = (uid.hashCode <= peerId.hashCode) ?
'$uid-$peerId' : '$peerId-$uid';We then check to see if the conversation has been previously deleted by checking if an end_at value exists. Once we get both chatId and end_at, we can finally fetch the messages:
Future<void> getInitialMessages() async {
final end = await Repo.chatEndAtForUser(peer.uid); final initialMessages =
await Repo.getMessages(chatId: chatId, endAt: end);
endAt = end;
if (initialMessages.isNotEmpty) {
startAt = initialMessages.last.timestamp;
}
setState(() {
messages.addAll(initialMessages);
initialMessagedFinishedLoading = true;
});
return;
}This is getMessages function — unlike posts, we paginate the Firestore query using Timestamp instead of DocumentSnapshot :
Future<List<ChatItem>> getMessages(String chatId, Timestamp endAt,
{Timestamp startAt}) async {
final ref = shared.collection('chats').document(chatId);
final limit = 20;
Query query;
query = endAt == null
? query = ref
.collection('messages')
.orderBy('timestamp', descending: true)
.limit(limit)
: startAt == null
? ref
.collection('messages')
.orderBy('timestamp', descending: true)
.endAt([endAt]).limit(limit)
: ref
.collection('messages')
.orderBy('timestamp', descending: true)
.startAfter([startAt]).endAt([endAt]).limit(limit);
final snap = await query.getDocuments();
return snap.documents.map((doc) => ChatItem.fromDoc(doc)).toList();
}The chat collection is located at the root level and contains the messages subcollection which contains all the messages and their content:

Once we have the messages, we can finally display them on the chat screen:

Every element you see in the chat ListView is powered by a ChatItem data object retrieved from Firestore. We use a switch statement to convert the ChatItem into its appropriate UI element based on its type, which the we use to populate theListView. This includes the white peer text bubble, the blue user text bubble, the timestamp, and the is typing indicator.
The chatListView is unique since it loads messages from the bottom and paginates/load more messages when the user scroll up. Essentially, the ListView is inverted. Luckily, ListView has one handy property reversed which we set to true in order to accommodate this behavior.
We need to find the right place to add the peer avatar and timestamps. In the ListView’s itemBuilder :
itemBuilder: (context, index) {
final message = messages[index];
final isPeer =
message.senderId != auth.uid;
///Remember: list view is reversed
final isLast = index < 1; final lastMessageIsMine =
isLast && !isPeer;
final nextBubbleIsMine =
(!isLast &&
messages[index - 1]
.senderId ==
auth.uid);
final showPeerAvatar = (isLast &&
message.senderId ==
peer.uid) ||
nextBubbleIsMine;
///Show message date if previous message is
///sent more than an hour ago
final isFirst =
index == messages.length - 1;
final currentMessage =
messages[index];
final previousMessage = isFirst
? null
: messages[index + 1]; ///Show timestamp
bool showDate;
if (previousMessage == null) {
showDate = true;
} else if (currentMessage
.timestamp ==
null ||
previousMessage.timestamp ==
null) {
showDate = true;
} else {
showDate = previousMessage
.timestamp.seconds <
currentMessage
.timestamp.seconds -
3600;
}Once you determine the showPeerAvatar and showDate boolean properties, you can inject them into whatever widget you use to populate the ListView.
Want to show if a user is typing? First, we listen to a TextEditingController attached to the TextField widget. Call this function in our initState:
///Current logged in user's uid
String uid = FirestoreService.ath.uid;///Listen to whether or not peer is typing
listenToTypingEvent() {
textController.addListener(() {
if (textController.text.isNotEmpty) {
///Use a flag to make sure not to call this multiple times if (!selfIsTyping) {
print('is typing');
Repo.isTyping(chatId, uid, true);
}
selfIsTyping = true;
} else {
selfIsTyping = false;
print('not typing!');
Repo.isTyping(chatId, uid, false);
}
});
}Don’t forget to stop showing typing activity when the chat screen is closed. We override the dispose() method:
@override
void dispose() {
print('dispose chat screen');
Repo.isTyping(chatId, uid, false);
super.dispose();
}The isTyping function writes to the chat’s is_typing subcollection — we do not need to set any data to it, just make sure the document is created or deleted with the user id as its document id:
isTyping(String chatId, String uid, bool isTyping) {
final ref = shared.collection('chats').document(chatId).collection('is_typing');
return isTyping
? ref.document(uid).setData({})
: ref.document(uid).delete();
}This allows us to create a stream which listens to which of the chat participants are typing:
Stream<QuerySnapshot> isTypingStream(String chatId) {
return shared
.collection('chats')
.document(chatId)
.collection('is_typing')
.snapshots();
}In our chat screen, we listen to this stream which inserts or removes a typing indicator:
_isTypingStream = Repo.isTypingStream(chatId);
_isTypingStream.listen((data) {
if (!mounted) return;
final uids = data.documents.map((doc) => doc.documentID).toList();
print(uids);
if (uids.contains(peer.uid)) {
///Ensure that only one typing indicator is visible
if (!peerIsTyping) {
peerIsTyping = true;
setState(() {
messages.insert(
0,
ChatItem(
type: Bubbles.isTyping,
),
);
});
}
} else {
print('should remove peer is typing');
peerIsTyping = false;
_removeMessageOfType(Bubbles.isTyping);
}
});When a user uploads a message, three writes are made — to the chat data bucket, the user’s DM data bucket, and the peer’s DM data bucket:
Future<void> uploadMessage({
String content,
User peer,
}) async {
final timestamp = Timestamp.now(); final messageRef = shared.collection('chats').document(chatId).collection('messages')
.document(); final selfRef = userRef(auth.uid).collection('chats').document(peer.uid);
final peerRef = userRef(peer.uid).collection('chats').document(auth.uid);
final selfMap = auth.user.toMap();
final peerMap = peer.toMap();
final payload = {
'sender_id': auth.uid,
'timestamp': timestamp,
'content': content,
'type': 'text',
};
final batch = shared.batch();
///Chat message ref
batch.setData(messageRef, payload);
///My DM chat ref
batch.setData(
selfRef,
{
'is_persisted': true,
'last_checked': payload,
'last_checked_timestamp': timestamp,
'user': peerMap,
},
merge: true);
///Peer DM chat ref
batch.setData(
peerRef,
{
'is_persisted': true,
'last_checked': payload,
'last_checked_timestamp': timestamp,
'user': selfMap,
},
merge: true);
return batch.commit();
}Depending on how you set your security rules, you might need to do the third write using a cloud function. There is actually an added benefit to these writes — the user data in the DM data bucket is automatically updated every time a message is sent. Therefore, we might not need to write a fan-out cloud operation that updates user data every time someone’s profile changes.
Stories
Stories is probably the most challenging feature to implement. Apart from the really complex UI, we also need a way to keep track of the stories that a user has seen. Additionally, there are several key differences between posts and moments, which I will discuss later.
There are 3 main widgets in play:
Inline Stories — this is the widget you see above the feed screen. Its main purpose is to show if the users you follow have uploaded at least a story in the past 24 hours.

Stories are written to a user’s feed in a similar way using a fan-out approach. When a user uploads a story, a cloud function gets triggered and writes the most recent story data to every follower’s story feed:
///This triggers a fan-out cloud function
Future uploadStory(
{@required DocumentReference storyRef, @required String url}) async {
return await storyRef.setData({
'timestamp': Timestamp.now(),
'url': url,
'uploader': auth.user.toMap(),
});
}The uploader’s user id is used as the document id. This means the collection can only have one document pertaining to an uploader.

The document contains the timestamp of the uploader’s most recent story which we use to query data for the widget.
Future<List<UserStory>> getStoriesOfFollowings() async {
final now = Timestamp.now();
final todayInSeconds = now.seconds;
final todayInNanoSeconds = now.nanoseconds;
///24 hours ago since now
final cutOff = Timestamp(todayInSeconds - 86400, todayInNanoSeconds);
final query = myProfileRef
.collection('story_feed')
.where('timestamp', isGreaterThanOrEqualTo: cutOff);
final snap = await query.getDocuments();
return snap.documents.map((doc) => UserStory.fromDoc(doc)).toList();
}We use getDocuments() without imposing a limit to fetch all of the users who have recently posted a story. This is the first big difference — unlike posts, we do not paginate the fetching of stories.
It is advisable to put a hard limit on the numbers of users we can follow, like on Instagram, to prevent abuse.
Now that we have the recent user stories, we need to indicate which ones contain stories that the user have not seen before by using a ring around the uploader’s avatar. If you don’t want to use a gradient for this indicator ring, you can simply use a Stack with a CircularProgressIndicator with a slightly bigger radius than the avatar:
CircularProgressIndicator(
valueColor: AlwaysStoppedAnimation<Color>(yourColor),
),You will need to maintain a stream that of the user stories you have viewed in the past 24 hours:
Stream<DocumentSnapshot> seenStoriesStream() =>
myProfileRef
.collection('seen_stories')
.document('list')
.snapshots();
This stream is maintained as a single document, where each field corresponds to an uploader and the value being the timestamp of latest story of the uploader that the user has viewed:

Take note that each firestore document has a 1MB size limit. However, in order to hit that limit, a user must have seen stories from tens of thousands of different users in a single day, which is extremely unlikely. This is because every time the document is updated, we do a little bit of spring cleaning to remove data that is more than a day old.
Future updateSeenStories(Map<String, Timestamp> data) async {
final now = Timestamp.now();
final todayInSeconds = now.seconds;
final todayInNanoSeconds = now.nanoseconds;
///24 hours ago since now
final cutOff = Timestamp(todayInSeconds - 86400, todayInNanoSeconds);
final ref = myProfileRef.collection('seen_stories').document('list');
final doc = await ref.get();
final stories = doc.data ?? {};
///Remove old data
stories.removeWhere((k, v) => v.seconds < cutOff.seconds);
stories.addAll(data);
return ref.setData(stories);
}We use the stream to get the StoryState of a particular UserStory where the state can be none, seen, or unseen. Inject the state into a StoryAvatar widget to make it show a colored/gradient ring if unseen, or show a thin grey circle if seen.
///The ListView inside the Inline Stories widget has a horizontal scroll directionreturn StreamBuilder<DocumentSnapshot>(
stream: Repo.seenStoriesStream(),
builder: (context, snapshot) {
if (!snapshot.hasData) return LoadingIndicator();
final seenStories = snapshot.data.data ?? {};
return ListView.builder(
... scrollDirection: Axis.horizontal,
itemCount: widget.userStories?.length ?? 0,
itemBuilder: (context, index) {
final userStory = widget.userStories[index];
final Timestamp seenStoryTimestamp =
seenStories[userStory.uploader.uid];
final storyState = userStory.lastTimestamp == null
? StoryState.none
: seenStoryTimestamp == null
? StoryState.unseen
: seenStoryTimestamp.seconds <
userStory.lastTimestamp.seconds
? StoryState.unseen
: StoryState.seen;
return StoryAvatar(
storyState: storyState,
...This updateSeenStories function gets called within the next widget which we will move on to.
Story PageView — This is the widget that opens up when a user taps on a user in the Inline Stories widget. The majority of the Stories experience lies within this widget.
Another big difference is that stories are loaded only when they are needed. Unlike posts which are always visible, stories are only shown when the user opens a user’s story or swipes to another user’s story. This is the behavior seen on Instagram, where a progress indicator is shown before stories are loaded.
The Story Page View is shown modally, like in Instagram. We call the method showModalBottomSheet and set the following fields to fill up the entire screen:
isScrollControlled: true,
useRootNavigator: true,This way, we can dismiss the StoryPageView by swiping down thanks to the in-built behavior found in BottomSheet .
However, I found that no matter what I do, it would not respect the SafeArea . Therefore, I had to manually specify a top padding so that the story header do not overlap with the system UI overlays.
The file contains these methods for navigating through the PageView :
previousPage() and nextPage() enables the PageView’sPageController to switch between pages with animation. We set the controllers’s initial page in initState() based on which user avatar was pressed in the InlineStories widget.
_pop() gets called whenever the user presses the cancel button located at the top right corner, or automatically when the the last story of the last page in the PageView has finished playing. It simply invokes Navigator.of(context).pop(), which closes the BottomSheet .
However, before we dismiss the StoryPageView, we need to update our seen_stories firestore document if there were new stories that the user saw. We accomplish this by calling Repo.updateSeenStories(Map<String, dynamic> data) in the dispose() method. We get the necessary data to upload from the onMomentChanged(int) callback of StoryView.

Each page in the PageView is a StoryView, the widget responsible for displaying the stories, keeping track of new stories the user have seen, determining which story to play first, and telling when to switch to another user’s stories.
The StoryView itself is a Stack widget containing another PageView that cycles through the story images using a MomentView.
A Stack widget is used to overlay the user header, progress bar indicator, and invisible gesture detectors on top of the PageView .
The progress indicator bar tracks the current story progress and shows how many pieces of story that each user has uploaded. Each piece is called a Moment and it contains the media url, upload date and the display duration.
Each StoryView contains an animation controller that handles the automatic playback of stories. We set the duration of the controller to the duration of the current moment in initState and resumes it in _play().
controller = AnimationController(
vsync: this,
duration: story.moments[momentIndex].duration,
)..addStatusListener((status) {
if (status == AnimationStatus.completed) {
switchToNextOrFinish();
}
});
_play();The _play function resumes the animation controller only if the image of the moment has been loaded:
///Resumes the animation controller
///provided the current moment has been loaded
void _play() {
if (story == null || widget.story == null) return;
if (story.moments.isEmpty) return;
///if momentIndex is not in range (due to deletion)
if (momentIndex > story.moments.length - 1) return;
if (story.moments[momentIndex].isLoaded) controller.forward();
}The topmost widget in the stack is a widget that detects user gestures, which we use to pause, resume and switch stories:
Positioned(
top: 120,
left: 0,
right: 0,
child: GestureDetector(
behavior: HitTestBehavior.opaque,
onTapDown: onTapDown,
onTapUp: onTapUp,
onLongPress: onLongPress,
onLongPressUp: onLongPressEnd,
),
),onTapDown stops the animation controller, while onTapUp decides whether to go the next or previous story based on horizontal position of the user gesture. onLongPress also stops the animation controller while turning the StoryView into a fullscreen mode by hiding the overlays (progress bar, user header, etc). The overlays are wrapped inside an AnimatedOpacity widget that listens to the value of isInFullscreenMode. onLongPressEnd reverts the isInFullscreenMode back to false and resumes the animation controller:
/// Sets the ratio of left and right tappable portions
/// of the screen: left for switching back, right for switching forward
final double momentSwitcherFraction = 0.26;onTapDown(TapDownDetails details) {
controller.stop();
}
onTapUp(TapUpDetails details) {
final width = MediaQuery.of(context).size.width;
if (details.localPosition.dx < width * widget.momentSwitcherFraction) {
switchToPrevOrFinish();
} else {
switchToNextOrFinish();
}
}
onLongPress() {
print('onlongpress');
controller.stop();
setState(() => isInFullscreenMode = true);
}
onLongPressEnd() {
print('onlongpress end');
setState(() => isInFullscreenMode = false);
_play();
}In switchToNextOrFinish, we check if the current moment is the last moment. If it is, we call widget.onFlashForward which triggers the StoryPageView to load an entirely new StoryView containing the story of the next user. If it is not the last moment, we tell the StoryView’s page controller to jump to the next image. We also reset the animation controller and resume it when the next image is loaded. switchToPrevOrFinish follows the same idea.
switchToNextOrFinish() {
controller.stop();
if (momentIndex + 1 >= story.moments.length) {
widget.onFlashForward();
} else {
controller.reset();
setState(() {
momentIndex += 1;
_momentPageController.jumpToPage(momentIndex);
});
controller.duration = story.moments[momentIndex].duration;
_play();
widget.onMomentChanged(momentIndex);
}
}
switchToPrevOrFinish() {
controller.stop();
if (momentIndex - 1 < 0) {
widget.isFirstStory ? onReset() : widget.onFlashBack();
} else {
controller.reset();
setState(() {
momentIndex -= 1;
_momentPageController.jumpToPage(momentIndex);
});
controller.duration = story.moments[momentIndex].duration;
_play();
widget.onMomentChanged(momentIndex);
}
}I used the flutter_instagram_stories package as a starting point and heavily reworked it for my app. The whole stories experience is a PageView (StoryView) within a PageView (StoryPageView) within a ListView (Inline Stories).
There are a lot of other stuff that I have not talked about, such as the activity screen, editor screen, explore screen, comment screen, account privacy, mentions, regex, using a unique username for authentication and more.
I also want to point out that Firebase is not a perfect solution if you want to build a complete Instagram experience. This goes back to the limited query capabilities of Firestore, and I have yet to figure out super complex queries like “fetch accounts that are similar to accounts you follow”.